The Problem Nobody Talks About

Zero-Knowledge Logging: Your logs encrypted before they leave your application
Every developer knows this uncomfortable truth: we’ve all accidentally logged sensitive data. Maybe it was a debug statement that printed the entire request object (headers and all). Maybe it was an error handler that dumped the database connection string. Maybe it was that helpful middleware that logs everything “just in case.”
But here’s what keeps me up at night: every major log aggregation service can read your logs.
Not “might be able to.” Not “theoretically could.” They can read them. Right now.
Think about that. Your logs probably contain:
- API keys that slipped through in request headers
- Customer data in error messages
- Internal service URLs and architecture details
- Session tokens, auth headers, and JWTs
- Database connection strings with embedded passwords
And all of this data sits readable in your log provider’s infrastructure. Their employees could read it. Anyone who breaches them could read it. Government requests could demand it.
This isn’t a hypothetical problem. Real breaches have started with log access:
- The LastPass breach in 2022 began with access to their development environment logs
- Toyota exposed source code through misconfigured Elasticsearch clusters containing logs
- CircleCI’s 2023 incident involved attackers accessing environment variables in build logs
But instead of making up a dramatic story, let me tell you why we actually decided to build a zero-knowledge log platform.
Why We Started Building This
I’ve been running production systems for over a decade. Every team I’ve worked with has had the same “oh shit” moment when someone realizes what’s actually in the logs. It usually happens during a security audit or compliance review:
“Hey, why can I see customer email addresses in these error logs?”
“Is that a Stripe API key in that debug output?”
“Wait, are we logging the entire request body including passwords?”
The traditional solutions are band-aids:
- Add redaction rules (that developers forget to update)
- Filter sensitive logs (losing debugging capability when you need it most)
- Trust your log provider’s security (hope they never get breached)
- Just… try to be careful (this always works, right?)
We realized there’s a fundamental problem: centralized logging requires centralized trust.
End-to-end encrypted logging — live now
Your data stays encrypted at all times. Even we cannot access your log content. Free tier included, no credit card required.
What’s Really in Your Logs?
Let’s be honest about what typically ends up in production logs. Here’s actual code I’ve seen in production systems (sanitized for obvious reasons):
The Classic Debug Statement
// "I'll remove this before deploying" - Famous last words
console.log('Payment processing:', {
user: userObject, // Contains email, phone, address
payment: paymentData, // Contains card details
config: stripeConfig // Contains API keys
});
The Helpful Error Handler
# Logs the entire stack trace with all local variables
logger.exception(f"Database error for user {user_id}", exc_info=True, extra={
'connection': str(db_connection), # Password in connection string
'query': query, # May contain PII
'environment': os.environ # ALL environment variables
})
The Overzealous Middleware
// "We need this for debugging production issues"
log.Printf("[REQUEST] %s %s Headers: %v Body: %s",
r.Method,
r.URL.String(), // May contain API keys in query params
r.Header, // Contains auth tokens
bodyBytes) // Contains... everything
The Third-Party Library That’s “Helping”
// Some ORM or HTTP client with verbose logging
[2024-01-15 10:23:45] DEBUG: Executing query:
SELECT * FROM users WHERE ssn='123-45-6789' AND password='plaintext_password'
[2024-01-15 10:23:45] DEBUG: Connection pool:
postgresql://admin:SuperSecret123@prod-db.internal:5432/customers
Run this simple check on your own logs (if you dare):
# Check for potential secrets in your logs
grep -iE '(api[_-]?key|password|token|secret|bearer|authorization)' /var/log/*.log | head -20
# Check for potential PII
grep -E '[0-9]{3}-[0-9]{2}-[0-9]{4}|[0-9]{4}[\s-]?[0-9]{4}[\s-]?[0-9]{4}[\s-]?[0-9]{4}' /var/log/*.log | head -20
The Current “Solutions” Don’t Actually Solve Anything
Manual Redaction: The Infinite Game of Whack-a-Mole
Every team tries to build a redaction layer:
function sanitizeLogs(data) {
const sensitiveFields = ['password', 'token', 'apiKey', 'secret', 'ssn'];
// ... 50 more fields added over time
// But what about:
// - nested objects?
// - different naming conventions (api-key vs apiKey vs api_key)?
// - base64 encoded data?
// - new fields that developers add tomorrow?
}
This fails because:
- It’s a blocklist approach in a world that needs allowlists
- Developers under pressure bypass it
- New sensitive fields appear constantly
- You’re still trusting your provider with everything else
The “We Trust Our Provider” Approach
“We use [BigCorp Cloud Logging]. They’re SOC2 compliant!”
Sure, but:
- Their employees can still read your logs
- Compliance doesn’t prevent breaches
- Subpoenas and government requests exist
- Their security isn’t your security
Enter Zero-Knowledge Logging
The Fundamental Shift
What if your log provider couldn’t read your logs, even if they wanted to? Not through policy, not through promises, but through cryptographic impossibility?
That’s what we built: Your logs are encrypted before they leave your application. Only you hold the keys.
How It Actually Works
Traditional Logging:
// What you write
logger.error('Payment failed', {
customerId: 'cust_8474',
amount: 99.99,
cardLast4: '4242'
});
// What your provider sees (EVERYTHING IN PLAINTEXT)
{
"message": "Payment failed",
"customerId": "cust_8474", // Readable
"amount": 99.99, // Readable
"cardLast4": "4242" // Readable
}
Zero-Knowledge Logging:
// What you write (exact same code)
logger.error('Payment failed', {
customerId: 'cust_8474',
amount: 99.99,
cardLast4: '4242'
});
// What your provider sees (LogEnvelope - ENCRYPTED)
{
"timestamp": "2025-09-03T10:30:45.123Z",
"entry_type": 1,
"payload_type": 1,
"payload": "U2FsdGVkX1+vJqK8Lm9pN3R4c5T6u7V8w9X0...",
"nonce": "YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4eXoxMjM0NTY="
}
The provider can still route, store, and search your logs using the tokens, but they can’t read the actual content. Ever.
The Architecture
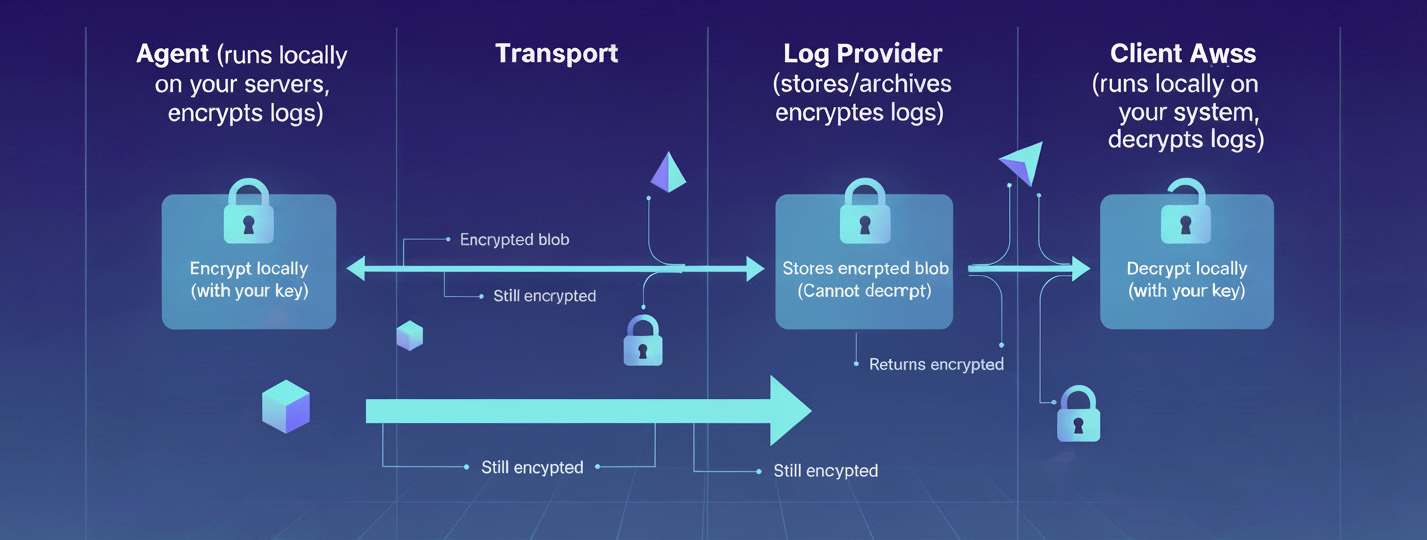
The flow is simple but powerful:
- Your Application → Agent (runs locally on your servers, encrypts logs)
- Agent → Log Provider (stores/archives encrypted logs)
- Log Provider → Client Apps (runs locally on your system, decrypts logs)
At no point does the Log Provider have access to your encryption keys or readable log content. They handle encrypted blobs that are meaningless without your keys.
The Compliance Superpower Nobody Expected
GDPR’s “Right to be Forgotten” - Actually Possible
With traditional logging:
- Logs are replicated everywhere
- Backups are immutable
- You need to hunt down every copy
- Derived data exists in analytics systems
- It’s basically impossible to truly delete
With zero-knowledge logging:
// Delete user data with one key deletion
async function deleteUserData(userId) {
// Delete the encryption key
await keyManager.deleteKey(`user:${userId}`);
// All logs for this user are now permanent noise
// No need to touch the actual log data
// No need to modify backups
// Cryptographic deletion - immediate and complete
}
Data Residency Without the Complexity
Traditional approach: Separate deployments per region, complex routing, data replication rules.
Our approach: Your encrypted logs can be stored anywhere. Data residency is controlled by where your keys live, not where the encrypted blobs are stored.
Of course, if your compliance requirements demand it, we also support traditional geographic data residency - keeping your encrypted logs in specific regions. But here’s the key difference: even with regional storage, your data remains encrypted with keys you control. So whether your logs are stored in Frankfurt, Singapore, or Virginia, the fundamental zero-knowledge principle holds - we can’t read them regardless of where they physically reside.
// Logs can be stored in US
const logger = new ZeroKnowledgeLogger({
logEndpoint: 'https://us-east-1.logprovider.com',
// But keys never leave EU
keyManagement: 'https://eu-keys.your-company.internal'
});
// Result: GDPR compliant even though logs are in US
The Hard Questions
“What if we lose access to our keys?”
This is a valid concern, but here’s the key point: we never have access to your keys in the first place.
Your encryption keys are generated and stored entirely on your side. LogFlux only ever sees encrypted data that we cannot decrypt. However, for the infrastructure keys that manage our service (not your data encryption keys), we do implement robust safeguards:
// LogFlux infrastructure key management
{
"service_keys": "Stored in HSM with multi-party access",
"backup_keys": "Distributed across secure locations",
"access_keys": "Multi-signature authentication required"
}
// Our key protection strategy
- Hardware security modules (HSMs) for critical infrastructure
- Multi-party key recovery procedures
- Secure backup procedures across geographic regions
- Clear incident response protocols
“How do we debug production issues?”
You maintain full debugging capability:
// Temporary decryption session for debugging
const debugSession = await createDebugSession({
duration: '1h',
scope: 'production-errors',
user: 'oncall-engineer@company.com',
reason: 'Investigating customer issue #1234'
});
// All access is audited
// Session auto-expires
// Logs remain encrypted at rest
“Isn’t this overkill for our startup?”
Consider the alternative:
- One leaked API key can kill your business
- One GDPR violation can cost 4% of global revenue
- One breach destroys customer trust forever
Starting with zero-knowledge is easier than retrofitting security later.
Why We Built This
We’re not trying to sell you on fear. We’re building this because:
- We’ve been burned before - Every engineer has accidentally leaked something in logs
- Trust shouldn’t be required - Good security doesn’t rely on promises
- Privacy is a feature - Your customers’ data should be protected by default
- Compliance should be simple - Cryptographic deletion beats complex data pipelines
Try This Yourself
Before you dismiss this as unnecessary, run this audit on your current logs:
# Quick check for common sensitive patterns
echo "Checking for potential secrets in logs..."
for pattern in 'password' 'token' 'api.?key' 'secret' 'authorization'; do
count=$(grep -i "$pattern" /var/log/*.log 2>/dev/null | wc -l)
if [ $count -gt 0 ]; then
echo "Found $count instances of '$pattern'"
fi
done
# Check for credit card patterns
echo -e "\nChecking for credit card patterns..."
grep -E '[0-9]{4}[\s-]?[0-9]{4}[\s-]?[0-9]{4}[\s-]?[0-9]{4}' /var/log/*.log 2>/dev/null | wc -l
If you find anything, you have a problem that needs solving.
The Path Forward
Zero-knowledge logging isn’t about paranoia. It’s about accepting reality:
- Breaches happen
- Mistakes happen
- Insider threats exist
- Compliance requirements are getting stricter
The question isn’t “Will someone try to read your logs?”
The question is “When they try, what will they find?”
With traditional logging: Everything.
With zero-knowledge logging: Encrypted noise.
Check out our approach at logflux.io. The future of logging isn’t about collecting more data - it’s about collecting data responsibly.